2 Search gene metadata
The genInfo() function helps users quickly search a batch of gene metadata, such as gene names, genomic location, GC content, and more.
2.1 Supported organisms
It supports 195 vertebrate species, 120 plant species, and two bacterial species. All data is kept up to date.
# install.packages('DT')
library(genekitr)
DT::datatable(ensOrg_name, options = list(pageLength = 10))Users can select an organism name from the latin_short_name column.
Common names are also acceptable for popular research species (e.g., human, mouse, rat, fly, zebrafish, worm, chicken). Taking human as an example, the official Latin short name is “hsapiens”, while “hg”, “hsa”, “hs”, and “human” are also acceptable.
2.2 Basic usage
genInfo only has three arguments:
id: gene ID (symbol, Entrez, or Ensembl) or protein IDorg: organism name, default is humanunique:TRUEorFALSE. Commonly, one gene may have multiple matched records of the same ID type. For example, the humanHBDgene has three matched Entrez IDs: 3045, 85349, and 100187828. If set toTRUE, only a one-to-one match with the smallest Entrez ID or the most complete information (i.e., the fewest NAs) will be returned. See genekitr feature2 for an example.
## [1] "input_id" "symbol" "entrezid" "ensembl"
## [5] "uniprot" "gene_name" "summary" "chr"
## [9] "start" "end" "width" "strand"
## [13] "ncbi_alias" "ensembl_alias" "gc_content" "gene_biotype"
## [17] "hgnc_id" "omim" "ccds" "reactome"
## [21] "ucsc" "mirbase_id" "cell_marker"
head(info, 3)## input_id symbol entrezid ensembl
## 1 TP53 TP53 7157 ENSG00000141510
## 2 BRCA1 BRCA1 672 ENSG00000012048
## 3 TET2 TET2 54790 ENSG00000168769
## uniprot
## 1 P04637; K7PPA8; A0A386NBZ1; A0A346XLR9; A0A514TT50; A0A514TT61; A0A346XM22; L0ENG9; S5M706; Q1HGV1; L0EQ05; A4GW67; U6BHT9; A0A218MJF3; L0ESB7; A0A514TT34; L0EPY0; Q1HGV3; A0A346XLP2; A0A346XM50; S5LQU8; A0A346XM43; S5LQX7; A0A346XLT2; Q1MSX0; A2I9Z2; A0A346XM39; A0A346XLY6; L0EQS1; A0A346XLY3; L0EQE2; A0A346XM06; Q1MSW9; L0ES54; A0A514TT40; L0EQ92; L0EQP9; A0A346XLR1; A0A346XLW0; L0EPV7; A0A346XLW4; A2I9Y7; A0A346XM49; A0A346XLX2; A0A218MJD5; A0A346XM05; A0A1B1PFC7; A0A346XM38; A0A1B1PFD4; S5LJ61; A4GWB5; L0EQU5; A2I9Z0; Q1MSW8; A0A346XLP0; A0A346XLX5; A0A346XLT0; A0A346XLU1; A0A346XLX3; A0A346XM28; A0A514TSZ6; J3KP33; H2EHT1; E7EQX7; E9PCY9; E7ESS1; E9PFT5; A0AAQ5BHX5; A0AAQ5BHY1; S4R334; A0A087X1Q1; E7EMR6; A0A0U1RQC9; I3L0W9; A0AAQ5BHZ9; A0A087WT22; A0A087WXZ1; L0EQQ9; Q19RW5; L0ES92; S5M713; B4XAL0; A0A346XLP8; A0A346XLP1; A0A386NG45; A0A386NDA8; A0A386NC22; L0EPW3; L0EPZ1; S5LJ49; A0A346XLT1; E2G6R5; Q0ZAK0; A0A386YR42; A0A346XLS5; A0A0A0U7X4; L0EP99; A0A346XLN9; A0A346XLP3; S5LQU3; B5AKF7; A0A386NFY2; L0ENF7; S5LME3; L0EQ03; A0A346XLP7; A0A346XLQ1; S5LMI5; A0A218MJB0; Q1HGV0; A0A1D8V7A7; A0A514TT13; A0A346XM51; A0A346XLS6; A0A386NC25; A0A0R9RRX7; U6BHU6; L0ERB4; Q0ZAK1; D5KL86; A4GW75; A0A346XM34; L0ERL2; A0A514TSZ1; A0A346XLW8; B5AKF6; Q2XSC7; U6BKV7; A0A346XLN8; A2I9Z1; A0A386NC62; A0A218MJD9; A0A386NC55; S5LJ04; A4GWD0; D5KL88; L0EQJ1; A0A346XLP5; L0ERJ3; A0A346XM40; A0A218MJE1; D5KL87; B5AKF5; D5KL90; U6BGT3; L0EQX9; A0A386NCW8; A4GW97; L0EP82; B4XAK8; A0A386NCB1; A0A346XLS7; B1PZ15; A0A386NC20; A0A346XLX0; Q0ZAJ9; Q19RW6; A0A514TT08; A0A346XLP9; L0ERK8; L0EQV3; S5LMG1; U6BI14; A0A0M4B4Y9; Q1HGV2; A0A386NCA6; A0A346XLP6; A4GW74; A0A514TT20; A0A514TSZ9; L0EQY4; A0A346XLS9; L0ESQ5; S5LMC6; A0A346XLT4; A0A218MJE5; A0A218MJC8; E5RMA8; A0A346XLS8; A0A386NCU2; K7PPU4; L0EQT1; S5M207; L0ERI9; L0ENG6; L0EPX4; A0A346XM56; A0A386NCX4; D5KL89; A4GWB4; L0EQ52; A0A514TT23; S5LQQ1; L0EQP1; L0EQ89; L0ERS6; A0A346XLT3; S5M224; A0A386NFX3; A0A3Q8QC73; A4GWB8; L0EQX3; L0ES73; A4GW76; A0A514TT49; A0A386NDB3
## 2 P38398; C6YB45; A0A068BDV0; Q3LRH8; E9PC22; A0A9Y1VVF6; E7ENB7; Q3B891; G1UI37; B4DES0; A0A9Y1QPT7; A0A9Y1VR53; A0A6B7FWY8; A0A3S8V3K0; G4V500; A0A068BCB8; Q3YB51; A0A140HIE5; Q9NQR3; A0A345G165; Q3YB49; A0A6B7FX59; A0A140HIE9; A0A6B7FU58; Q3YB52; Q92897; A0A482E6X8; A0A0F7GA54; A0A6B7FW63; A0A6B7FUC3; A0A6B7FX01; A0A068BFY0; A0A345G162; Q3YB53; A0A068BI55; A0A6B7FU28; A0A6B7FU85; A0A6B7FVL7; A0A0K0QR99; A0A2R4U2D7; A0A6B7FU98; A0A8E6MK24; E7EQW4; A0A386INN6; A0A7G8KP81; A0AA49K9I7; A0A2R8Y7V5; K7EJW3; Q5XLT4; A0A8V8TPY7; Q7KYU6; Q5U3B7; A0A386IPW7; A0A386IN41; A0AA49K9A2; A0A6G8IUS2; A0A386INH9; A0A9Y1QQL7; A0A386IQ66; A0A9Y1QQF4; A0A3G1CIM0; A0A9Y1QQ02; A0A386IQ64; H0Y8D8; A0A649UB25; A0A386INP3; A0A9Y1VVE2; A0A386IN42; A0A7G8KP79; E7EUM2; A0A9Y1VVD0; A0A4P8DKQ8; A0A386IPW4; A0A386IN60; A0A9Y1QPY6; A0A0U1RRA9; H0Y850; K7EPC7; A0A4P8DLA0; A0A9Y1QQ22; A0A386IN52; A0A386INP8; A0A9Y1QQK5; A0A386IN53; A0A649U8H0; A0A386INJ5; G8I0D8; A0A2R8Y6Y9; A0A386IPW3; A0A386IPY5; A0A6G8IU30; A0A9Y1QQ47; E7EWN5; A0A7G8KP80; A0A386INQ5; A0A9Y1VUM8; A0A9Y1VVF5; A0A9Y1QQF1; A0A386IPW2; A0A3G1CIL2; A0A386IPA8; A0AA49K9C2; A0A8F2JD03; A0A386IPL0; A0A386IPB0; A0AA49K9C3; H0Y8B8; A0A9E8Z2K8; A0A9Y1QQK3; A0A386IPW1; A0A9Y1QQK7; A0A386IPK6; A0A9Y1QQD3; C9IZW4; A0A9Y1QPQ7; A0A9Y1QQJ6; A0AA49K9S0; A0A386IPY7; A0A0F7G9Q0; A0A0F7G9S0; C6YB47; A0A9Y1QPR4; A0A386IN34; A0A494C182; A0A8F2F4Q1; Q05BZ9; A0AA49K9A1; A0A6G8IU58; G4V4Z7; Q4EW25; Q8IZT7; A0A6B7FUW4; A0A6B7FU53; K4JWE8; G4V502; A0A6B7FUA0; A0A6B7FUX9; A0A6B7FW56; K4K7U9; A0A0F6TMZ3; A0A345G166; A0A6B7FUE8; A0A6C0W937; K4JTS0; A0A068BCB6; A0A0F6RAC9; Q3YB50; Q64FK1; A0A0G3FC22; A0A6B7FU56; C4PFY7; A0A2P1MAS5; A0A6B7FVI4; A0A068BFW2; A0A6B7FU93; H6TXS1; A0A6B7FW87; A0A068BDT2; A0A068BC97; A0A068BI32; A0A0K0PUK0; A0A0F6TMQ0; A0A6B7FXA3; A0A6B7FVJ1; A0A068BFV4; A0A0K0QRF6; A0A0U4JQJ0; A0A068BEV3; A0A0G3FCF2; A0A3Q8UCB1; Q3B890; A0A386IPY8; K4JUB6; A0A6B7FV02; A0A068BCA1; A0A6B7FU78; A0A068BFV9; A0A386L1T8; A0A6B7FUB2; A0A068BFX7; A0A6B7FUA6; Q7Z606; A0A0R9RX69; K4JXT2; A0A068BEV6; A0A068BDU7; A0A068BI44; A0A0F6TN86; A0A290YM93; A0A0A1ESW9; G4V503; Q64FK2; K4JUB1; Q8IZK2; G4V4Z8; A0A386IQ58; A0A386IN33; A0A386IN29; A0A068BI36; A0A2R4U2D8; K4K7V3; A0A6B7FX64; A0A6B7FU81; A0A6B7FU97; Q8IZK4; A0A0F6RAD1; A0A2R4U2F8; A0A6B7FVM6; A0A6B7FUD8; A0A068BEW5; A0A0F6RAU2; A0A6B7FUA2; A0A068BI53; A0A3G1CIL4; A0A6B7FU68; A0A0U4JDF9; A0A068BEU9; Q8IU58; A0A6B7FVK7; A0A482E729; A0A6B7FX04; A0A6B7FX81; A0A6G8IU28; A0A8A2FK90; A0A068BI42; A0A068BDT6; A0A0K0PU93; A0A068BCB2; A0A345G163; A0A0F6TN19; Q6P671; Q64FK3; A0A0F6TNH6; A0A068BCA4; A0A068BDT9; Q9UE29; A0A0F7GBC5; Q8IZK3; A0A6B7FU72; A0A345G161; A0A4P8DL17; K4JXS7; A0A0K0PU86; A0A8E6MBR0; A0A6B7FU90; A0A0N9E014; A0A068BC99; A0A068BI38
## 3 Q6N021; A7E237; D6RE87; A0A158SIU0; E7EQS8; E7EPB1; L8E8T1
## gene_name
## 1 tumor protein p53
## 2 BRCA1 DNA repair associated
## 3 tet methylcytosine dioxygenase 2
## summary
## 1 This gene encodes a tumor suppressor protein containing transcriptional activation, DNA binding, and oligomerization domains. The encoded protein responds to diverse cellular stresses to regulate expression of target genes, thereby inducing cell cycle arrest, apoptosis, senescence, DNA repair, or changes in metabolism. Mutations in this gene are associated with a variety of human cancers, including hereditary cancers such as Li-Fraumeni syndrome. Alternative splicing of this gene and the use of alternate promoters result in multiple transcript variants and isoforms. Additional isoforms have also been shown to result from the use of alternate translation initiation codons from identical transcript variants (PMIDs: 12032546, 20937277). [provided by RefSeq, Dec 2016]
## 2 This gene encodes a 190 kD nuclear phosphoprotein that plays a role in maintaining genomic stability, and it also acts as a tumor suppressor. The BRCA1 gene contains 22 exons spanning about 110 kb of DNA. The encoded protein combines with other tumor suppressors, DNA damage sensors, and signal transducers to form a large multi-subunit protein complex known as the BRCA1-associated genome surveillance complex (BASC). This gene product associates with RNA polymerase II, and through the C-terminal domain, also interacts with histone deacetylase complexes. This protein thus plays a role in transcription, DNA repair of double-stranded breaks, and recombination. Mutations in this gene are responsible for approximately 40% of inherited breast cancers and more than 80% of inherited breast and ovarian cancers. Alternative splicing plays a role in modulating the subcellular localization and physiological function of this gene. Many alternatively spliced transcript variants, some of which are disease-associated mutations, have been described for this gene, but the full-length natures of only some of these variants has been described. A related pseudogene, which is also located on chromosome 17, has been identified. [provided by RefSeq, May 2020]
## 3 The protein encoded by this gene is a methylcytosine dioxygenase that catalyzes the conversion of methylcytosine to 5-hydroxymethylcytosine. The encoded protein is involved in myelopoiesis, and defects in this gene have been associated with several myeloproliferative disorders. Two variants encoding different isoforms have been found for this gene. [provided by RefSeq, Mar 2011]
## chr start end width strand
## 1 17 7661779 7687546 25768 -1
## 2 17 43044295 43170245 125951 -1
## 3 4 105145875 105279816 133942 1
## ncbi_alias
## 1 BCC7; BMFS5; LFS1; P53; TRP53
## 2 BRCAI; BRCC1; BROVCA1; FANCS; IRIS; PNCA4; PPP1R53; PSCP; RNF53
## 3 IMD75; KIAA1546; MDS
## ensembl_alias gc_content gene_biotype hgnc_id omim
## 1 LFS1; P53 48.86 protein_coding HGNC:11998 191170
## 2 BRCC1; FANCS; PPP1R53; RNF53 44.09 protein_coding HGNC:1100 113705
## 3 FLJ20032; KIAA1546 36.29 protein_coding HGNC:25941 612839
## ccds
## 1 CCDS73967; CCDS73966; CCDS73968; CCDS73964; CCDS73965; CCDS73963; CCDS73969; CCDS45606; CCDS45605; CCDS73970; CCDS73971; CCDS11118
## 2 CCDS11453; CCDS11456; CCDS11459; CCDS11455; CCDS11454
## 3 CCDS3666; ; CCDS47120
## reactome
## 1 R-HSA-1643685; R-HSA-392499; R-HSA-597592; R-HSA-109582; R-HSA-168249; R-HSA-168256; R-HSA-2262752; R-HSA-8953897; R-HSA-212436; R-HSA-73857; R-HSA-74160; R-HSA-162582; R-HSA-5688426; R-HSA-5689880; R-HSA-1266738; R-HSA-2990846; R-HSA-3108232; R-HSA-5693532; R-HSA-73894; R-HSA-109581; R-HSA-109606; R-HSA-114452; R-HSA-1257604; R-HSA-5357801; R-HSA-9006925; R-HSA-1640170; R-HSA-69278; R-HSA-69620; R-HSA-3700989; R-HSA-5633008; R-HSA-6803207; R-HSA-5218859; R-HSA-166016; R-HSA-166166; R-HSA-168164; R-HSA-168898; R-HSA-937061; R-HSA-157118; R-HSA-6807070; R-HSA-8943724; R-HSA-983231; R-HSA-2559583; R-HSA-8853884; R-HSA-6796648; R-HSA-453274; R-HSA-69275; R-HSA-1912408; R-HSA-1912422; R-HSA-6803204; R-HSA-8878159; R-HSA-9816359; R-HSA-9819196; R-HSA-390466; R-HSA-390471; R-HSA-391251; R-HSA-1280215; R-HSA-449147; R-HSA-69481; R-HSA-6785807; R-HSA-2559580; R-HSA-2559585; R-HSA-349425; R-HSA-446652; R-HSA-69541; R-HSA-69563; R-HSA-69580; R-HSA-69615; R-HSA-8852276; R-HSA-9020702; R-HSA-3232118; R-HSA-5693565; R-HSA-5693606; R-HSA-166058; R-HSA-168179; R-HSA-168188; R-HSA-181438; R-HSA-5633007; R-HSA-6804756; R-HSA-69473; R-HSA-9645723; R-HSA-9734009; R-HSA-5689896; R-HSA-8941855; R-HSA-2559586; R-HSA-5628897; R-HSA-6804757; R-HSA-6804759; R-HSA-6806003; R-HSA-6803211; R-HSA-913531; R-HSA-1169410; R-HSA-5620971; R-HSA-168138; R-HSA-168142; R-HSA-168176; R-HSA-168181; R-HSA-975138; R-HSA-975155; R-HSA-975871; R-HSA-445989; R-HSA-9833482; R-HSA-6804754; R-HSA-9758274; R-HSA-6804758; R-HSA-139915; R-HSA-6803205; R-HSA-6791312; R-HSA-6804115; R-HSA-6804114; R-HSA-6804116; R-HSA-69560; R-HSA-69895; R-HSA-2559584; R-HSA-6804760; R-HSA-6811555; R-HSA-111448; R-HSA-9723905; R-HSA-9723907
## 2 R-HSA-1643685; R-HSA-392499; R-HSA-597592; R-HSA-2262752; R-HSA-8953897; R-HSA-9711123; R-HSA-9755511; R-HSA-212436; R-HSA-73857; R-HSA-74160; R-HSA-5688426; R-HSA-2990846; R-HSA-3108214; R-HSA-3108232; R-HSA-5685938; R-HSA-5693532; R-HSA-5693538; R-HSA-5693567; R-HSA-73894; R-HSA-1640170; R-HSA-69620; R-HSA-8951664; R-HSA-3700989; R-HSA-6796648; R-HSA-69481; R-HSA-5693565; R-HSA-5693606; R-HSA-1474165; R-HSA-1221632; R-HSA-1500620; R-HSA-5633007; R-HSA-5685942; R-HSA-5689901; R-HSA-5693537; R-HSA-5693554; R-HSA-5693568; R-HSA-5693571; R-HSA-5693579; R-HSA-5693607; R-HSA-5693616; R-HSA-6804756; R-HSA-69473; R-HSA-8953750; R-HSA-912446; R-HSA-9663199; R-HSA-9675135; R-HSA-9675136; R-HSA-9699150; R-HSA-9701190; R-HSA-9701192; R-HSA-9701193; R-HSA-9704331; R-HSA-9704646; R-HSA-9709570; R-HSA-9709603
## 3 R-HSA-74160; R-HSA-212165; R-HSA-1474165; R-HSA-9827857; R-HSA-5221030
## ucsc
## 1 uc002gig.2; uc284ohw.1; uc031qyq.2; uc002gih.5; uc060auo.1; uc060aup.1; uc060auq.1; uc010cnf.2; uc010cng.2; uc002gii.2; uc002gij.4; uc060aus.1; uc060aut.1; uc010cnh.4; uc060auu.1; uc060avb.2; uc060avd.2; uc060auz.2; uc060auv.1; uc060aur.2; uc060auy.2; uc060avc.2; uc002gim.5; ; uc010cnj.2; uc060ava.1; uc032esw.3
## 2 uc060frx.2; uc060fsc.2; uc060frn.2; uc002icq.6; uc060frz.2; uc060frv.2; uc060fri.1; uc060fro.2; uc060fry.2; uc002ict.5; uc287jed.2; uc284oig.2; uc060fsa.2; uc316duo.1; uc060fru.2; uc060fsd.2; uc060frs.2; uc285oal.2; uc002icu.4; uc316dup.1; uc285oaj.2; uc060frm.2; uc010whm.3; uc010whn.3; uc060frj.1; uc010cyx.4; uc060frk.1; uc060frl.1; uc060frp.1; uc316dyk.1; uc060frq.1; uc002idd.6; uc316dyl.1; uc060frw.1; uc285oak.1; uc316dym.1; uc060fsb.1; uc316duq.1; uc316dyn.1; uc316dyo.1
## 3 uc021xqk.1; uc011cez.3; uc062ysb.1; uc003hxj.3; uc003hxk.5; uc062ysc.1; uc010ilp.3; uc062yse.1; uc062ysf.1
## mirbase_id
## 1 <NA>
## 2 <NA>
## 3 <NA>
## cell_marker
## 1 Fetal gonad|T|Mitotic fetal germ cell; Fetal gonad|T|Gonadal endothelial cell; Fetal kidney|T|Natural killer T (NKT) cell; Fetal gonad|N|Mitotic fetal germ cell; Fetal gonad|N|Gonadal endothelial cell; Fetal kidney|N|Natural killer T (NKT) cell
## 2 Fetal kidney|T|Natural killer T (NKT) cell; Fetal kidney|N|Natural killer T (NKT) cell
## 3 Embryo|T|Trophectoderm cell; Liver|T|Exhausted CD8+ T cell; Liver|T|Regulatory T (Treg) cell; Fetal kidney|T|Natural killer T (NKT) cell; Embryo|N|Trophectoderm cell; Liver|T|Exhausted CD8+ T cell; Liver|T|Regulatory T (Treg) cell; Fetal kidney|N|Natural killer T (NKT) cell2.3 Features
2.3.1 f1: keep input order
The genInfo output will strictly follow the input order.
If a gene ID is unrecognized (e.g., misspelled or not found in the specified organism), the corresponding row will be filled with NA.
id <- c(
"MCM10", "CDC20", "S100A9",
"FAKEID", "TP53", "HBD", "NUDT10"
)
# for human id, no need to input the org argument
info <- genInfo(id, unique = TRUE)
identical(id, info$input_id)## [1] TRUE
head(info, 3)## input_id symbol entrezid ensembl uniprot
## 1 MCM10 MCM10 55388 ENSG00000065328 Q7L590; Q5T670; C9J600
## 2 CDC20 CDC20 991 ENSG00000117399 Q12834
## 3 S100A9 S100A9 6280 ENSG00000163220 P06702
## gene_name
## 1 minichromosome maintenance 10 replication initiation factor
## 2 cell division cycle 20
## 3 S100 calcium binding protein A9
## summary
## 1 The protein encoded by this gene is one of the highly conserved mini-chromosome maintenance proteins (MCM) that are involved in the initiation of eukaryotic genome replication. The hexameric protein complex formed by MCM proteins is a key component of the pre-replication complex (pre-RC) and it may be involved in the formation of replication forks and in the recruitment of other DNA replication related proteins. This protein can interact with MCM2 and MCM6, as well as with the origin recognition protein ORC2. It is regulated by proteolysis and phosphorylation in a cell cycle-dependent manner. Studies of a similar protein in Xenopus suggest that the chromatin binding of this protein at the onset of DNA replication is after pre-RC assembly and before origin unwinding. Alternatively spliced transcript variants encoding distinct isoforms have been identified. [provided by RefSeq, Jul 2008]
## 2 CDC20 appears to act as a regulatory protein interacting with several other proteins at multiple points in the cell cycle. It is required for two microtubule-dependent processes, nuclear movement prior to anaphase and chromosome separation. [provided by RefSeq, Jul 2008]
## 3 The protein encoded by this gene is a member of the S100 family of proteins containing 2 EF-hand calcium-binding motifs. S100 proteins are localized in the cytoplasm and/or nucleus of a wide range of cells, and involved in the regulation of a number of cellular processes such as cell cycle progression and differentiation. S100 genes include at least 13 members which are located as a cluster on chromosome 1q21. This protein may function in the inhibition of casein kinase and altered expression of this protein is associated with the disease cystic fibrosis. This antimicrobial protein exhibits antifungal and antibacterial activity. [provided by RefSeq, Nov 2014]
## chr start end width strand
## 1 10 13161558 13211110 49553 1
## 2 1 43358981 43363203 4223 1
## 3 1 153357854 153361023 3170 1
## ncbi_alias
## 1 CNA43; DNA43; IMD80; PRO2249
## 2 CDC20A; OOMD14; OZEMA14; bA276H19.3; p55CDC
## 3 60B8AG; CAGB; CFAG; CGLB; L1AG; LIAG; MAC387; MIF; MRP14; NIF; P14; S100-A9
## ensembl_alias
## 1 CNA43; DNA43; PRO2249
## 2 CDC20A; P55CDC
## 3 60B8AG; CAGB; CFAG; CGLB; LIAG; MAC387; MIF; MRP-14; MRP14; NIF; P14; S100-A9
## gc_content gene_biotype hgnc_id omim ccds
## 1 43.59 protein_coding HGNC:18043 609357 CCDS7095; ; CCDS7096
## 2 52.17 protein_coding HGNC:1723 603618 CCDS484
## 3 52.56 protein_coding HGNC:10499 123886 CCDS1036
## reactome
## 1 R-HSA-1640170; R-HSA-69278; R-HSA-69620; R-HSA-69002; R-HSA-69306; R-HSA-176187; R-HSA-453279; R-HSA-68962; R-HSA-69206; R-HSA-69481
## 2 R-HSA-392499; R-HSA-597592; R-HSA-168256; R-HSA-162582; R-HSA-194315; R-HSA-195258; R-HSA-5688426; R-HSA-5689880; R-HSA-9716542; R-HSA-1280218; R-HSA-141424; R-HSA-141444; R-HSA-1640170; R-HSA-2467813; R-HSA-2500257; R-HSA-2555396; R-HSA-5663220; R-HSA-68877; R-HSA-68882; R-HSA-68886; R-HSA-69278; R-HSA-69618; R-HSA-69620; R-HSA-9648025; R-HSA-983168; R-HSA-983169; R-HSA-141405; R-HSA-141430; R-HSA-174048; R-HSA-174143; R-HSA-174154; R-HSA-174178; R-HSA-174184; R-HSA-176407; R-HSA-176408; R-HSA-176409; R-HSA-176814; R-HSA-179409; R-HSA-179419; R-HSA-453276; R-HSA-174113; R-HSA-176417
## 3 R-HSA-1643685; R-HSA-168249; R-HSA-168256; R-HSA-6798695; R-HSA-162582; R-HSA-194315; R-HSA-195258; R-HSA-9716542; R-HSA-1280218; R-HSA-983169; R-HSA-166016; R-HSA-168898; R-HSA-5668599; R-HSA-1236974; R-HSA-1236975; R-HSA-6803157; R-HSA-166058; R-HSA-168179; R-HSA-168188; R-HSA-181438; R-HSA-5260271; R-HSA-5602358; R-HSA-5602498; R-HSA-5603041; R-HSA-6799990; R-HSA-5686938
## ucsc
## 1 uc001imb.4; uc057rtn.1; uc001ima.4; uc057rto.1; uc057rtp.1; uc057rtq.1; uc057rtr.1
## 2 uc001cix.5; uc001ciy.4; uc057fmt.1; uc057fmu.1
## 3 uc001fbq.4
## mirbase_id
## 1 <NA>
## 2 <NA>
## 3 <NA>
## cell_marker
## 1 Fetal gonad|T|Migration phase fetal germ cell; Umbilical cord blood|T|Granulocyte-monocyte progenitor; Fetal gonad|N|Migration phase fetal germ cell; Umbilical cord blood|N|Granulocyte-monocyte progenitor
## 2 Embryonic prefrontal cortex|T|Neural progenitor cell; Muscle|T|Myoblast; Large intestine|T|MKI67+ progenitor cell; Embryonic prefrontal cortex|N|Neural progenitor cell; Muscle|N|Myoblast; Large intestine|N|MKI67+ progenitor cell
## 3 Small intestine|T|Enterocyte progenitor cell; Fetal gonad|T|Granulosa cell; Blood|T|CD1C+_B dendritic cell; Fetal kidney|T|Monocyte; Kidney|T|Neutrophil; Kidney|T|Plasma cell; Kidney|T|Neutrophil; Undefined|N|Eosinophil; Undefined|N|Neutrophil; Bone marrow|N|Monocyte derived dendritic cell; Small intestine|N|Enterocyte progenitor cell; Fetal gonad|N|Granulosa cell; Blood|N|CD1C+_B dendritic cell; Fetal kidney|N|Monocyte; Kidney|N|Neutrophil; Kidney|T|Plasma cell; Kidney|T|Neutrophil2.3.2 f2: keep unique or not
If unique = TRUE, only one record with the most complete information is returned.
id <- "HBD"
uniq_info <- genInfo(id, org = "hs", unique = TRUE)
uniq_info[, 1:4]## input_id symbol entrezid ensembl
## 1 HBD HBD 3045 ENSG00000223609
all_info <- genInfo(id, org = "hs", unique = FALSE)
all_info[, 1:4]## input_id symbol entrezid ensembl
## 1 HBD HBD 3045 ENSG000002236092.3.3 f3: disambiguation feature
2.3.3.1 Distinguishing gene symbols from aliases
Many commonly used gene names are actually gene aliases, but most tools only accept official gene symbols, which can cause important information to be lost. For example, “BCC7” is an alias of “TP53”, and “PD1” has three aliases: “PDCD1”, “SNCA”, and “SPATA2” — yet few enrichment analysis tools are able to recognize aliases such as “BCC7”.
## input_id symbol entrezid ensembl
## 1 BCC7 TP53 7157 ENSG00000141510
## 2 PD1 PDCD1 5133 ENSG00000188389
## 3 PD1 PDCD1 5133 ENSG00000276977
## 4 PD1 SNCA 6622 ENSG00000145335
## 5 PD1 SPATA2 9825 ENSG000001584802.3.3.2 Distinguishing gene symbols with special characters
## input_id symbol entrezid ensembl
## 1 TNF-α TNF 7124 ENSG00000206439
## 2 TNF-α TNF 7124 ENSG00000206439
## 3 TNF-α TNF 7124 ENSG00000204490
## 4 TNF-α TNF 7124 ENSG00000204490
## 5 TNF-α TNF 7124 ENSG00000230108
## 6 TNF-α TNF 7124 ENSG00000230108
## 7 TNF-α TNF 7124 ENSG00000228849
## 8 TNF-α TNF 7124 ENSG00000228849
## 9 TNF-α TNF 7124 ENSG00000223952
## 10 TNF-α TNF 7124 ENSG00000223952
## 11 TNF-α TNF 7124 ENSG00000232810
## 12 TNF-α TNF 7124 ENSG00000232810
## 13 TNF-α TNF 7124 ENSG00000228321
## 14 TNF-α TNF 7124 ENSG00000228321
## 15 TNF-α TNF 7124 ENSG00000228978
## 16 TNF-α TNF 7124 ENSG00000228978
## 17 TNF-α TNF-alpha <NA> <NA>
## 18 κB-Ras2 NKIRAS2 28511 ENSG00000168256
## 19 κB-Ras2 NKIRAS2 28511 ENSG000001682562.3.4 f4: count organism gene types
org <- "hs"
uniq_symbol <- genInfo(org = org) %>%
dplyr::filter(!is.na(gene_biotype)) %>%
dplyr::distinct(symbol, .keep_all = T)
uniq_symbol %>%
{
table(.$gene_biotype)
}##
## artifact IG_C_gene
## 7 14
## IG_C_pseudogene IG_D_gene
## 8 37
## IG_J_gene IG_J_pseudogene
## 18 3
## IG_V_gene IG_V_pseudogene
## 144 185
## lncRNA miRNA
## 7416 1852
## misc_RNA Mt_rRNA
## 1031 2
## Mt_tRNA processed_pseudogene
## 23 7548
## protein_coding ribozyme
## 19794 5
## rRNA rRNA_pseudogene
## 346 499
## scaRNA scRNA
## 43 1
## snoRNA snRNA
## 834 1910
## sRNA TEC
## 1 30
## TR_C_gene TR_D_gene
## 6 5
## TR_J_gene TR_J_pseudogene
## 79 4
## TR_V_gene TR_V_pseudogene
## 107 33
## transcribed_processed_pseudogene transcribed_unitary_pseudogene
## 278 73
## transcribed_unprocessed_pseudogene translated_processed_pseudogene
## 460 2
## unitary_pseudogene unprocessed_pseudogene
## 80 1755
## vault_RNA
## 42.3.5 f5: extract all metadata
If you only want to retrieve all available information, simply provide the org argument alone.
## [1] 231602 222.3.6 f6: extract specific biotype genes
2.3.6.0.1 Get all human protein-coding genes:
hg_pro_gene <- uniq_symbol %>%
dplyr::filter(gene_biotype == "protein_coding") %>%
dplyr::pull(symbol)
length(hg_pro_gene)## [1] 197942.3.6.0.2 Compare with HGNC data:
hgnc_data <- vroom::vroom("http://ftp.ebi.ac.uk/pub/databases/genenames/hgnc/tsv/locus_types/gene_with_protein_product.txt")
hgnc_symbol <- hgnc_data$symbol
plotVenn(list(
genekitr_symbol = hg_pro_gene,
hgnc_symbol = hgnc_symbol
))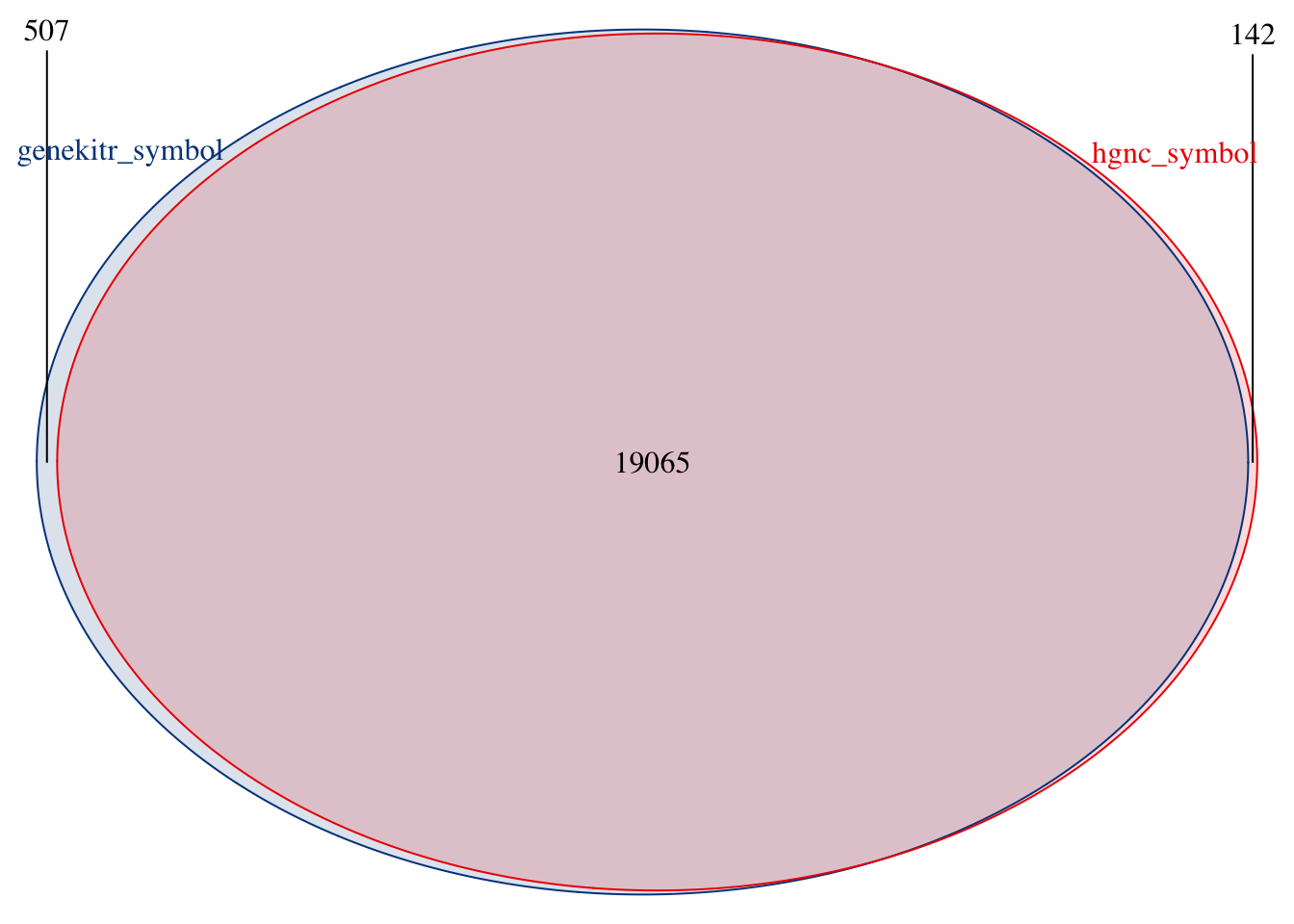
Let’s check some gene names missing from our result:
check_genes <- head(hgnc_symbol[!hgnc_symbol %in% hg_pro_gene], 3)
hgnc_data %>%
dplyr::filter(symbol %in% check_genes) %>%
dplyr::select(
symbol, date_approved_reserved, date_symbol_changed,
entrez_id
)## symbol date_approved_reserved date_symbol_changed entrez_id
## 1 ANXA8 1991-08-12 <NA> 653145
## 2 ATP6V1FNB 2018-04-26 <NA> 100130705
## 3 ATXN8 2006-07-18 <NA> 724066Let’s take a look at the first one, “ABTB3”:
It seems that the gene “ABTB3” was recently renamed; it is also known as “BTBD11”, which matches our Ensembl data: ENSG00000151136
genInfo("121551")[1:3]## input_id ensembl symbol
## 1 121551 ENSG00000151136 ABTB3So the reason for this mismatch is that the two large databases, Ensembl and NCBI, are not perfectly synced with each other. However, since the number of such mismatches is small, the overall effect is minor.
Here is my personal take on this:
NCBI updates its backend data daily, while Ensembl follows a quarterly update cycle.
As long as our gene data isn’t too outdated, it can still support downstream annotation tasks such as enrichment analysis. I wouldn’t recommend keeping gene names as up to date as NCBI, because other large databases simply can’t keep pace with such a high update frequency.
For example, the gene “BTBD11” (BTB/POZ domain-containing protein 11) is recognized by GeneOntology, while its newer name, “ABTB3”, hasn’t been synced yet. If you use the NCBI name instead, you might miss out on related enrichment information for this gene.
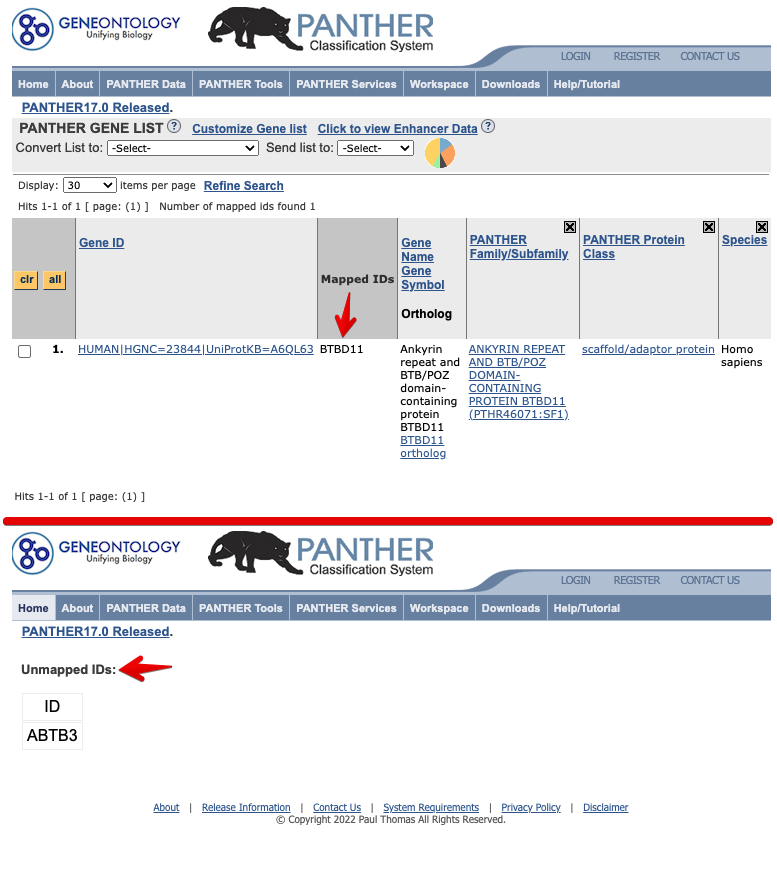
Figure 2.1: BTBD11 vs ABTB3 in GeneOntology
2.3.6.0.3 Compare with orgDb in Bioconductor
Since genekitr combines both Ensembl and NCBI data, it can handle more gene IDs than the common organism-level (org) packages available in Bioconductor.
# using orgdb
library(org.Hs.eg.db)
org_dat = AnnotationDbi::select(org.Hs.eg.db,
keys = AnnotationDbi::keys(org.Hs.eg.db),
keytype = 'ENTREZID',
columns = 'SYMBOL')
org_sym <- unique(org_dat$SYMBOL)
length(org_sym)## [1] 61538## [1] 199069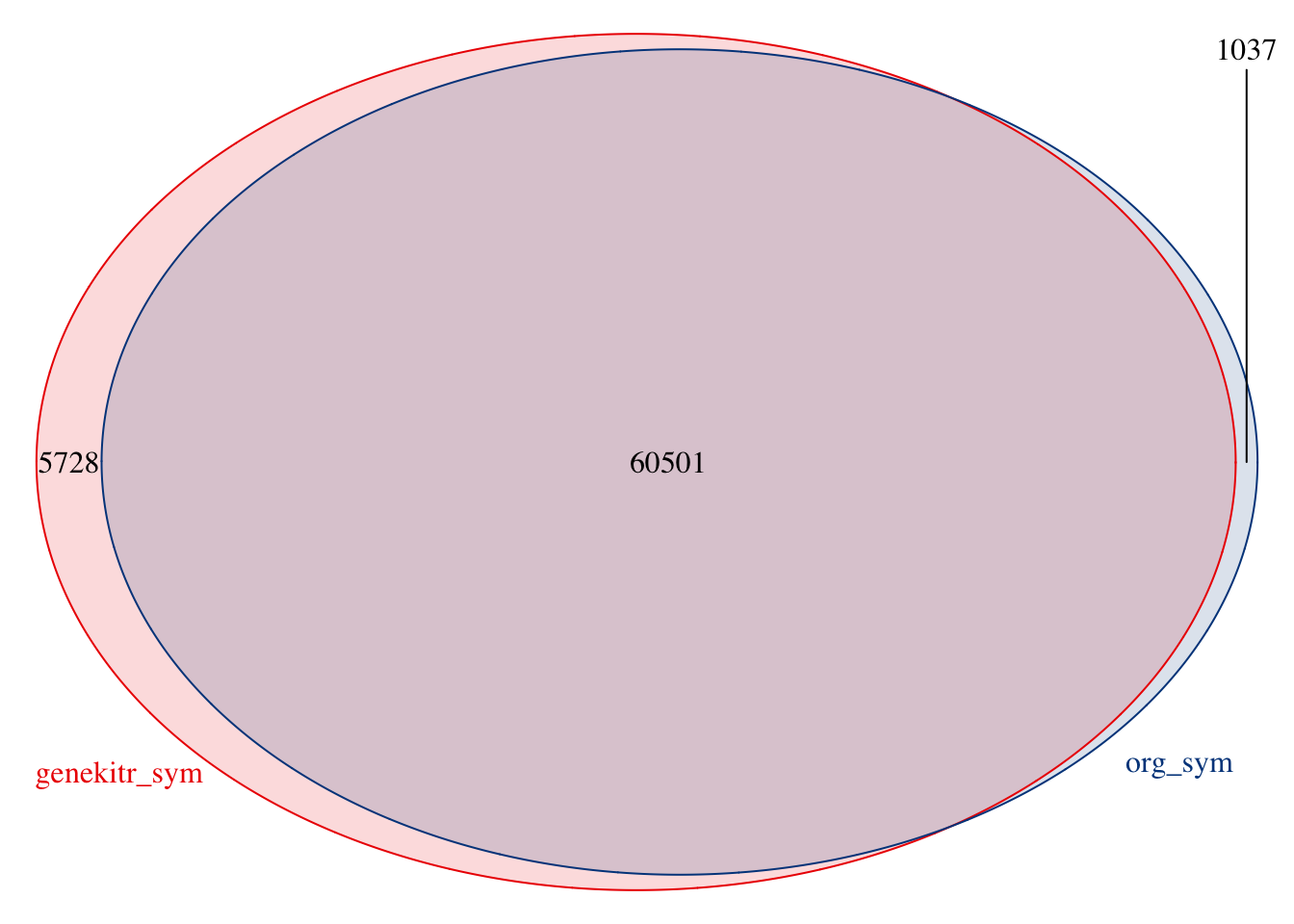
Some genes only exist in genekitr:
## [1] "DPPA4P3" "TMX1P1" "TMX1P2" "FKBP6P1" "SPDYE12" "GPCPD1P1"
genInfo("SPDYE12")[1:4]## input_id symbol entrezid ensembl
## 1 SPDYE12 SPDYE12 100101268 ENSG00000184616For example, gene 100101268 is officially named SPDYE12, while in orgDb its name is:
org_dat[org_dat$ENTREZID=="100101268","SYMBOL"]## [1] "SPDYE12P"Don’t worry — if you use genekitr, you can still get an exact match:
genInfo("SPDYE12P")[1:4]## input_id symbol entrezid ensembl
## 1 SPDYE12P SPDYE12 100101268 ENSG00000184616